






TL;DR: RunPod is my go-to for renting cloud GPUs. It’s the most practical way for AI hobbyists and developers to access serious power for tools like Flux/Stable Diffusion and text-to-speech models like Chatterbox without buying expensive hardware.
While there’s a learning curve, its wide selection of GPUs (pocket-friendly to Enterprise-grade), low hourly cost, and pre-built templates is hard to beat. Explore RunPod templates
Let’s be honest: building a powerful AI workstation is expensive. A single high-end GPU like an RTX 4090 can easily cost $2,000 – and that’s before you factor in the CPU, RAM, power supply, and cooling.
For many AI enthusiasts and developers, that price tag is simply out of reach. I was in that boat. That’s why I started using Runpod.
I have been using it for 7 months now and it has become my go-to for renting cloud GPUs.
Here’s my detailed RunPod review, covering its features, pricing, pros, cons, and if it’s worth it.
What is RunPod?
RunPod is a cloud platform that lets you rent powerful GPUs by the hour to run AI models. This means you don’t have to buy or manage physical hardware yourself.
It’s perfect for AI enthusiasts who want cloud GPUs for tasks like AI image generation with Stable Diffusion/ComfyUI/Flux. You can also use it for voice generation with open-source TTS models like Tortoise, and LLM chat.
Programmers can even connect VS Code and Cursor to LLM pods on RunPod.
How to get started
You have two main options for using AI models on RunPod.
- You can spin up temporary GPU pods for interactive tasks, just like on your own computer. This is called pod deployments.
- Alternatively, you can deploy code that runs only when needed, saving costs when idle through serverless APIs.
Best RunPod Features
1. Wide Selection of GPUs Globally
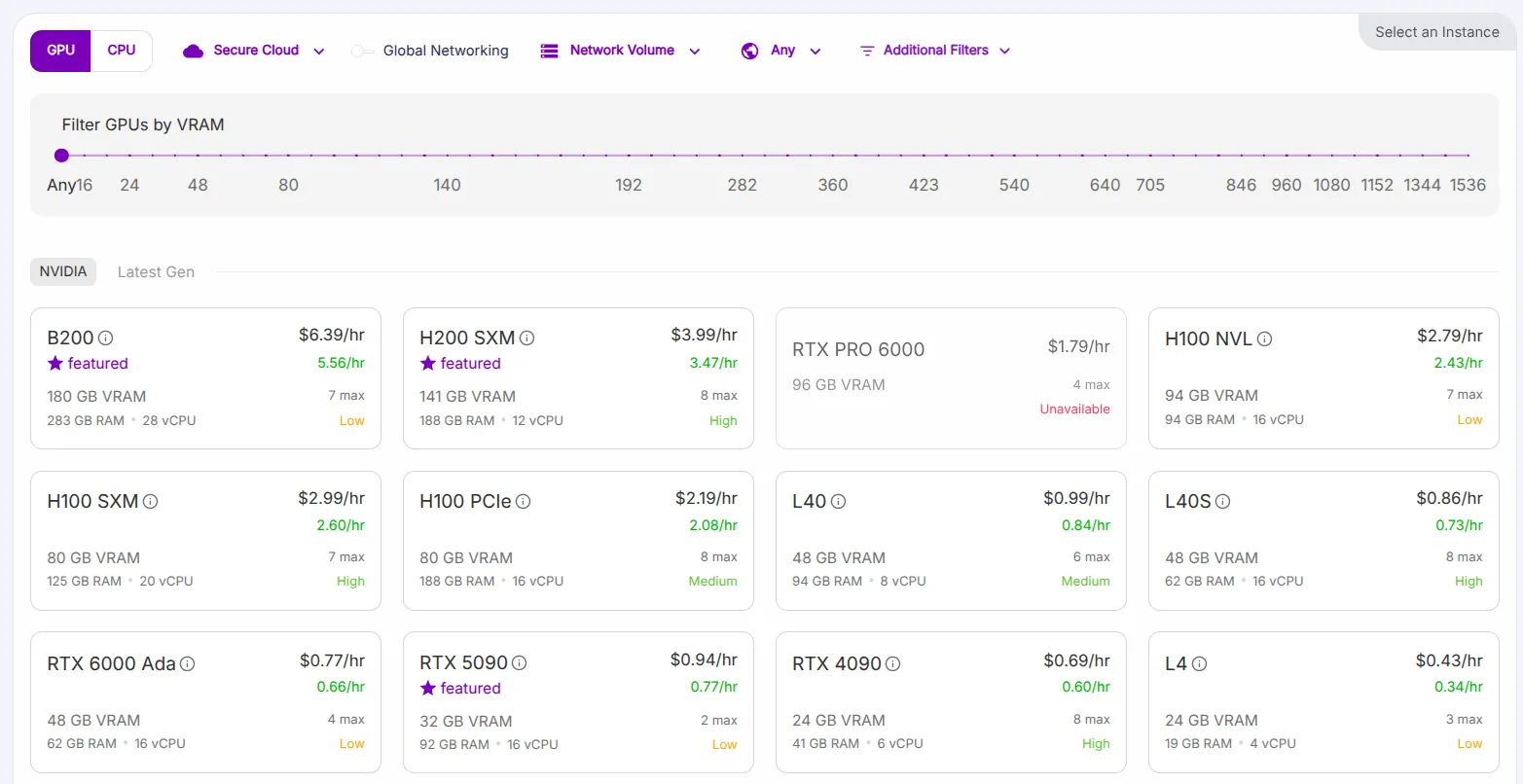 One of RunPod’s biggest strengths is the variety of GPUs and regions available. You can choose from NVIDIA’s latest cards, including H100, A100 80GB, and RTX 4090. High-VRAM enterprise GPUs like the A6000 48GB and A40 are also available.
One of RunPod’s biggest strengths is the variety of GPUs and regions available. You can choose from NVIDIA’s latest cards, including H100, A100 80GB, and RTX 4090. High-VRAM enterprise GPUs like the A6000 48GB and A40 are also available.
They even offer newer AMD GPUs, such as the MI300X with a massive 192 GB VRAM. With thousands of GPUs across 30+ data center regions worldwide, availability is typically high and latency is low.
2. Templates for Stable Diffusion, ComfyUI, etc.
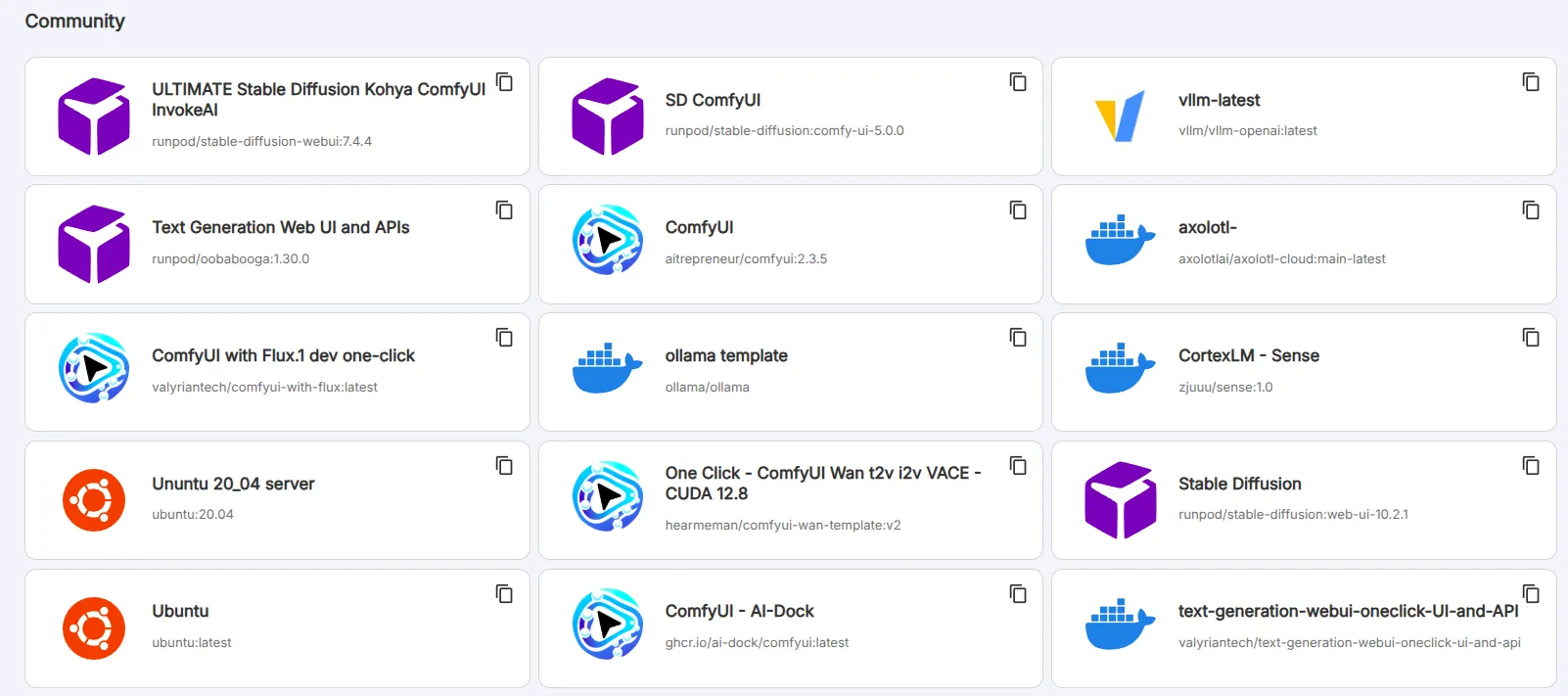 RunPod has 50+ pre-configured templates that make it very plug-and-play for common AI tasks. These templates simplify deployment significantly.
RunPod has 50+ pre-configured templates that make it very plug-and-play for common AI tasks. These templates simplify deployment significantly.
For example, you’ll find templates for PyTorch and TensorFlow environments, Stable Diffusion Automatic1111 web UI, ComfyUI, and Jupyter notebooks. If you want to generate images, you can simply select the “Fast Stable Diffusion” or Flux template and deploy – no manual setup required.
3. Flexible Usage/Pricing
RunPod provides two primary modes of operation: GPU Pods and Serverless. Each offers distinct advantages depending on your needs.
With Pods, you get a dedicated GPU machine (containerized) where you can run anything you want. This is ideal for interactive work, training, or custom setups.

You can also opt for beefy GPUs which are more expensive but top of the line.
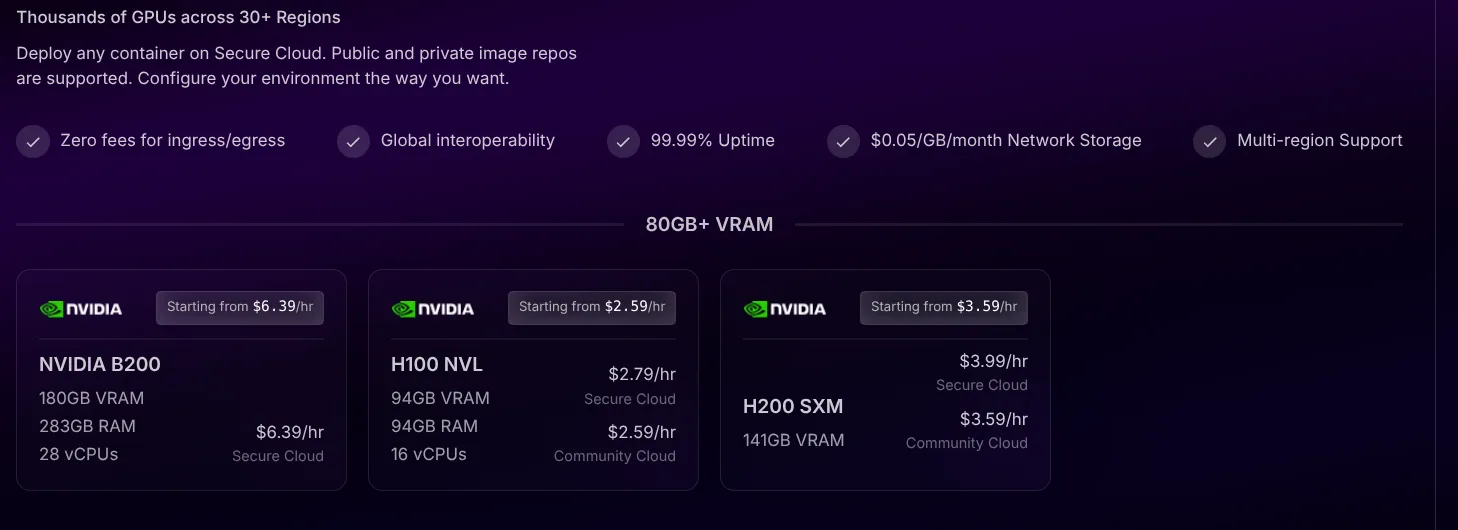
With Serverless endpoints, you deploy a piece of code, like an ML model inference API. This setup can autoscale and only incurs costs when processing requests.
Most users experimenting with Stable Diffusion or chatbots will likely stick to the Pod approach for simplicity. However, if you run a company or have an AI SaaS, you can use their serverless endpoints to serve customers. This is perfect for workflows like AI image upscaling or ComfyUI workflows.
4. Fast Startup, Performance Optimizations
RunPod pods cold-start in seconds; in some cases, they’ve cut cold-boot times to milliseconds. This means you can get to work almost immediately after hitting deploy.
The platform uses Docker containers under the hood for workload isolation. It also supports pulling public or private container images if you have a custom setup.
RunPod provides features like network file storage, allowing you to attach a persistent volume to retain data between sessions. You also get metrics and logging for your pods or endpoints.
Advanced users will appreciate the ability to use RunPod’s API/CLI to script deployments or manage Instant Clusters of multiple GPUs. For example, RunPod’s serverless offerings now support multi-GPU assignments (e.g., two 80GB GPUs, or up to ten 24GB GPUs in one job) to handle giant models that wouldn’t fit on a single card.
5. Additional Perks
There are a few other features worth noting that enhance the RunPod experience.
At the time of writing, RunPod does not charge for data ingress/egress (transfer). This means downloading large models or datasets to your pod won’t incur extra fees.
The platform also boasts a vibrant community Discord and a comprehensive knowledge base with tutorials.
Lastly, for those who like tinkering, RunPod supports custom environment variables, SSH access, and even bringing your own Docker image. This makes it very flexible if the provided templates ever feel limiting.
RunPod Pricing Explained
RunPod uses a pay-as-you-go pricing model. Hourly rates are determined by the GPU type and your choice between Secure Cloud or Community Cloud. You deposit credit (via credit card or even crypto) and then consume that balance as you run workloads.
GPU Hourly Rates: Prices range from around $0.16/hr up to ~$2.50/hr per GPU, depending on hardware. For example, a mid-tier NVIDIA RTX A5000 (24GB) is about $0.29/hr on Secure Cloud, or as low as $0.16/hr on Community Cloud.
A very popular choice for image generation, the RTX 3090 (24GB), costs roughly $0.43/hr (Secure) or $0.22/hr (Community). On the high end, an NVIDIA A100 80GB (suitable for large LLMs or SDXL) is about $1.64/hr (Secure) or $1.19/hr (Community).
In general, the pricing is quite competitive compared to major clouds. Plus, there’s no long-term commitment, making it perfect for short-term tasks.
Secure vs. Community Cloud
The difference here lies in the underlying infrastructure. It’s essentially enterprise data center GPUs versus vetted private-provider GPUs.
Secure Cloud pods run in Tier 3/4 data centers, offering guaranteed reliability (99.99% uptime) and robust power/network redundancy. This option provides maximum stability.
Community Cloud pods are provided by third-party hosts (individuals or smaller data centers) that meet RunPod’s standards. While they may not have the same level of redundancy, they are often 20-30% cheaper.
Most hobby users opt for Community Cloud to save money and typically find it perfectly adequate for tasks like Stable Diffusion. Both options charge only the hourly rate when the pod is running.
On-Demand vs. Spot
By default, RunPod gives you on-demand pods. This means you can run them for as long as you want, with guaranteed availability.
They also offer a Spot market where you can bid for cheaper rates. This is an option if you’re okay with your pod potentially shutting down when higher-priority demand comes in. Spot pods can be interrupted with a ~5 second warning, allowing you to save state to a volume.
I recommend on-demand for most users unless your budget is really small. This ensures uninterrupted work.
Storage and Data Costs
As mentioned, network traffic is free (no surprise bandwidth bills). This is a significant advantage when dealing with large models and datasets.
Persistent storage volumes cost $0.05 per GB per month. For example, a 100GB volume would be $5/month.
The storage cost while your pod is stopped is basically the only cost you incur when a pod is not running. So, if you spin up a pod, then shut it down but keep a volume attached for next time, you only pay pennies for the stored data until you need the GPU again.
RunPod is excellent for stop-and-go AI usage: you pay only for the resources you actually use while a pod is running.
But remember to shut off your pod when done to avoid continuing charges (a common gotcha with any cloud service).
In summary, RunPod is cost-effective for short-term AI tasks. You can spend just a few dollars to get several hours of access to a high-end GPU, complete your Stable Diffusion image generations or model fine-tuning, and then shut it down.
Performance
In practical terms, a RunPod GPU pod gives you nearly the same performance as you’d get running your task on a locally-owned GPU of that model. There is minimal overhead introduced by the containerization. The hardware is pass-through, so Stable Diffusion or training jobs can fully leverage the GPU’s CUDA cores and VRAM.
Another highlight is the fast startup times discussed earlier, often under 1 second. This contributes to a highly responsive experience.
Consistency and Reliability
Because RunPod spans a wide range of providers, you might wonder if performance is always uniform. In Secure Cloud (the professional data center pods), performance is very consistent. You have dedicated resources and strong network connectivity, ensuring reliability.
In Community Cloud, performance can vary slightly depending on the host’s setup. However, hosts are vetted to meet RunPod’s standards, maintaining a good baseline.
Latency and Throughput
If you’re connecting to a pod’s web interface from the same region, latency is low. This provides a smooth interactive experience.
If you use their serverless endpoints for something like an API, the typical overhead is a few hundred milliseconds cold start. After that initial start, you get realtime inference speed.
For example, RunPod demonstrated ~600ms cold start times on a 70B Llama model when configured with their optimized serverless setup.
All said, RunPod’s performance is strong and suitable for demanding AI workloads. You can confidently run Stable Diffusion, voice synthesis, or large language models on this platform.
How Easy is RunPod to Use?
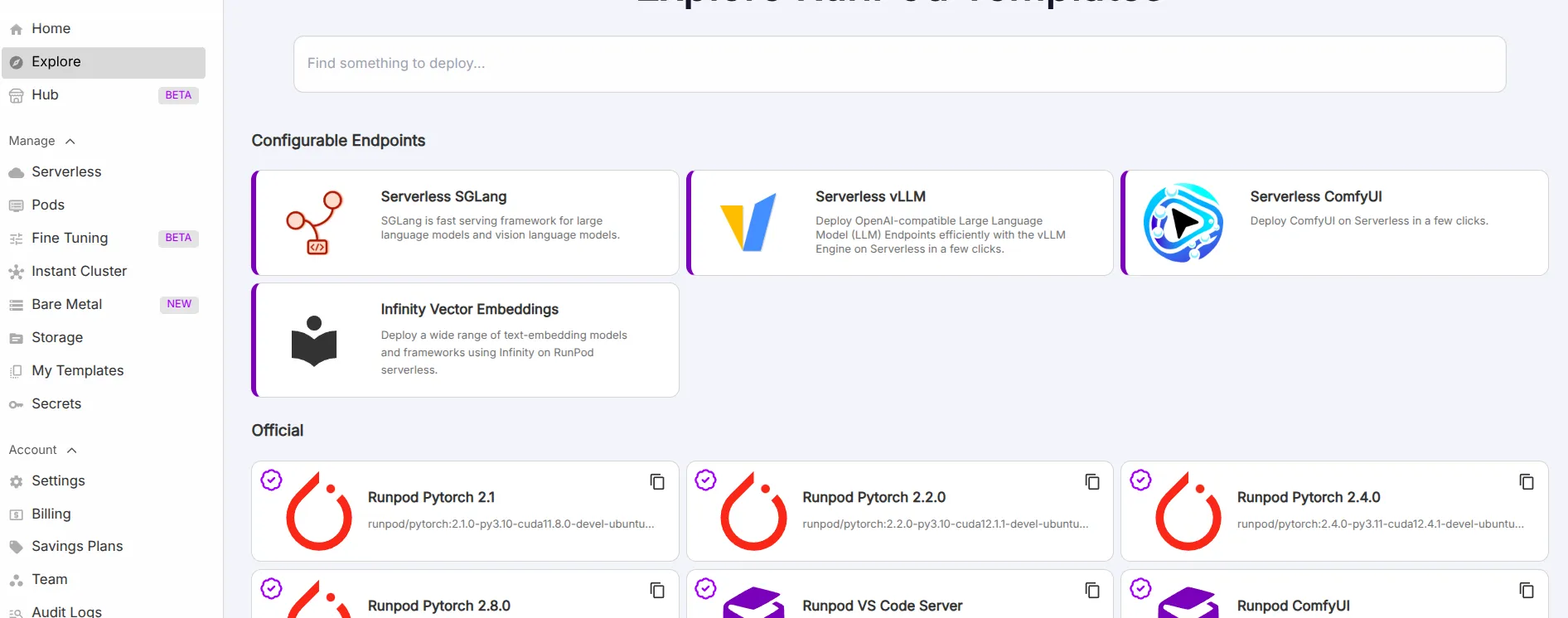
RunPod caters to both beginners and advanced users. It provides an easy on-ramp with templates, alongside full flexibility for custom setups.
Use their templates if you are not comfortable with SSH and Docker. These templates simplify the process significantly.
The templates come with all dependencies pre-installed (CUDA, diffusers, web server, etc.). This means literally no technical setup is needed beyond selecting your GPU and template.
If you prefer full control, RunPod doesn’t box you in. You can start with a base image, such as the official PyTorch template or just an Ubuntu+CUDA environment. Then, you can SSH in or use the web terminal to install exactly what you need.
For example, for a less common AI tool not available as a template (like a specific voice cloning repo), you could deploy a basic PyTorch pod. Then, you’d simply follow the project’s install instructions. The web-based terminal and JupyterLab access are very convenient here. You don’t need to fiddle with your own SSH keys unless you want to; you can open a terminal in the browser to run git clone or pip install commands directly.
RunPod even allows launching VS Code Server or other IDEs if you prefer a GUI development environment. This adds another layer of convenience for developers.
Workflow and Interface
The platform’s web console is straightforward and intuitive. It clearly lists your active pods, showing their status, cost, and options to connect (via HTTP or via SSH/TCP).
When a pod is running, you can open a web UI for any service the template provides. The template documentation will tell you which ports correspond to which service (e.g., Stable Diffusion’s web UI might be on port 7860, ComfyUI on 8188, etc.), and the console provides direct buttons for these.
For example, using the Better Forge Stable Diffusion template, the Connect menu gives you a “launcher” on one port. From there, you can one-click install additional UIs (like switching between Automatic1111 or ComfyUI) and then launch the UI of choice.
This kind of polish makes it very user-friendly. You don’t have to manually set up port forwarding or worry about tunnels; RunPod handles it. If you do need to expose an API or connect an external application (like SillyTavern for chatting with an LLM), the docs explain how to grab the proper endpoint URLs/ports from the console.
To summarize user-friendliness: RunPod is as easy or as advanced as you need it to be. You can treat it like a plug-and-play AI workstation, thanks to one-click templates for Stable Diffusion, ComfyUI, Jupyter, etc. Alternatively, it can function as a flexible cloud server, allowing you to install anything and use custom Docker images.
Customer Support
Documentation is good and official customer support is readily available and earnest. You can talk to humans for assistance. The Discord is quite active with both RunPod staff and experienced users hanging out to answer questions. If you run into an issue (like a pod not booting, or confusion about a template), posting on Discord often gets you near-real-time help.
There have been times when RunPod team members spent the whole day just talking with me and helping me fix minor issues. This level of dedication is impressive.
For a tech-savvy user, many issues you might encounter can be self-solved with docs or community advice.